
[PKOS STUDY #4] - Prometheus & Grafana

이정훈님의 ‘24단계 실습으로 정복하는 쿠버네티스’ 기반으로 작성된 포스팅 입니다. 도서 링크 : http://www.yes24.com/Product/Goods/115187666

실습환경 배포
- kops 인스턴스 t3.small & 노드 c5a.2xlarge (AMD vCPU 8, Memory 16GiB) 배포 : 이번주 실습에서 성능을 요구하는 파드를 사용함
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - aws cloudformation deploy --template-file kops-oneclick-f1.yaml --stack-name mykops --parameter-overrides KeyName=yuran SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID='xxxx' MyIamUserSecretAccessKey='xxxx+xxxxx+' ClusterBaseName='yuran.link' S3StateStore='yuran06141' MasterNodeInstanceType=c5a.2xlarge WorkerNodeInstanceType=c5a.2xlarge --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text
# 13분 후 작업 SSH 접속
ssh -i ~/.ssh/kp-gasida.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
# EC2 instance profiles 에 IAM Policy 추가(attach) : 처음 입력 시 적용이 잘 안될 경우 다시 한번 더 입력 하자! - IAM Role에서 새로고침 먼저 확인!
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
Metrics-server :
kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소 - 링크 Docs CMD
- cAdvisor : kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
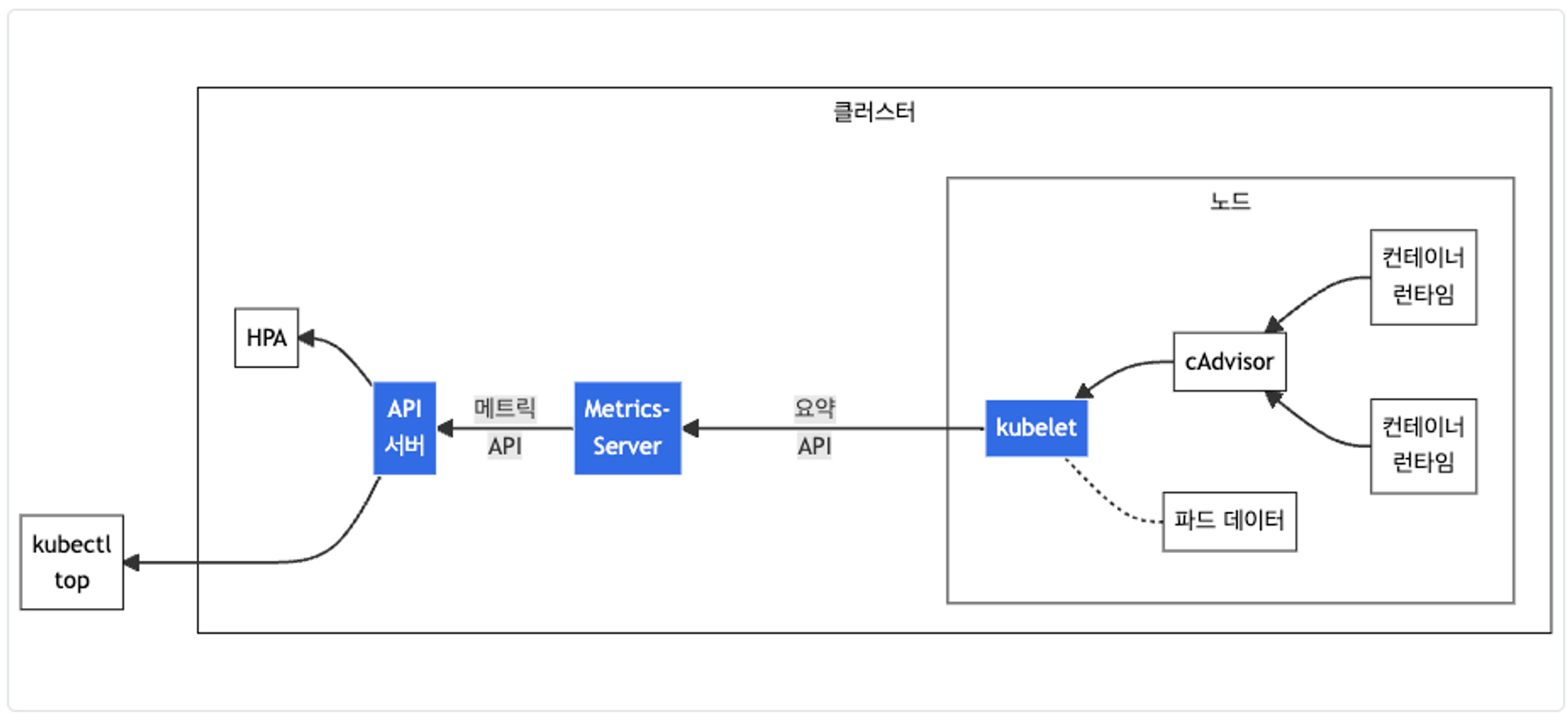
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'
프로메테우스 Prometheus
Prometheus is an open-source monitoring and alerting toolkit originally developed by SoundCloud. It is designed to help you observe and measure the performance and availability of your software systems. Prometheus collects metrics from your target systems, stores them in a time-series database, and provides a flexible query language to analyze the data. It also includes a powerful alerting system that can notify you when specific conditions are met. Prometheus is widely used in cloud-native environments and is often used alongside other tools such as Kubernetes for container orchestration.
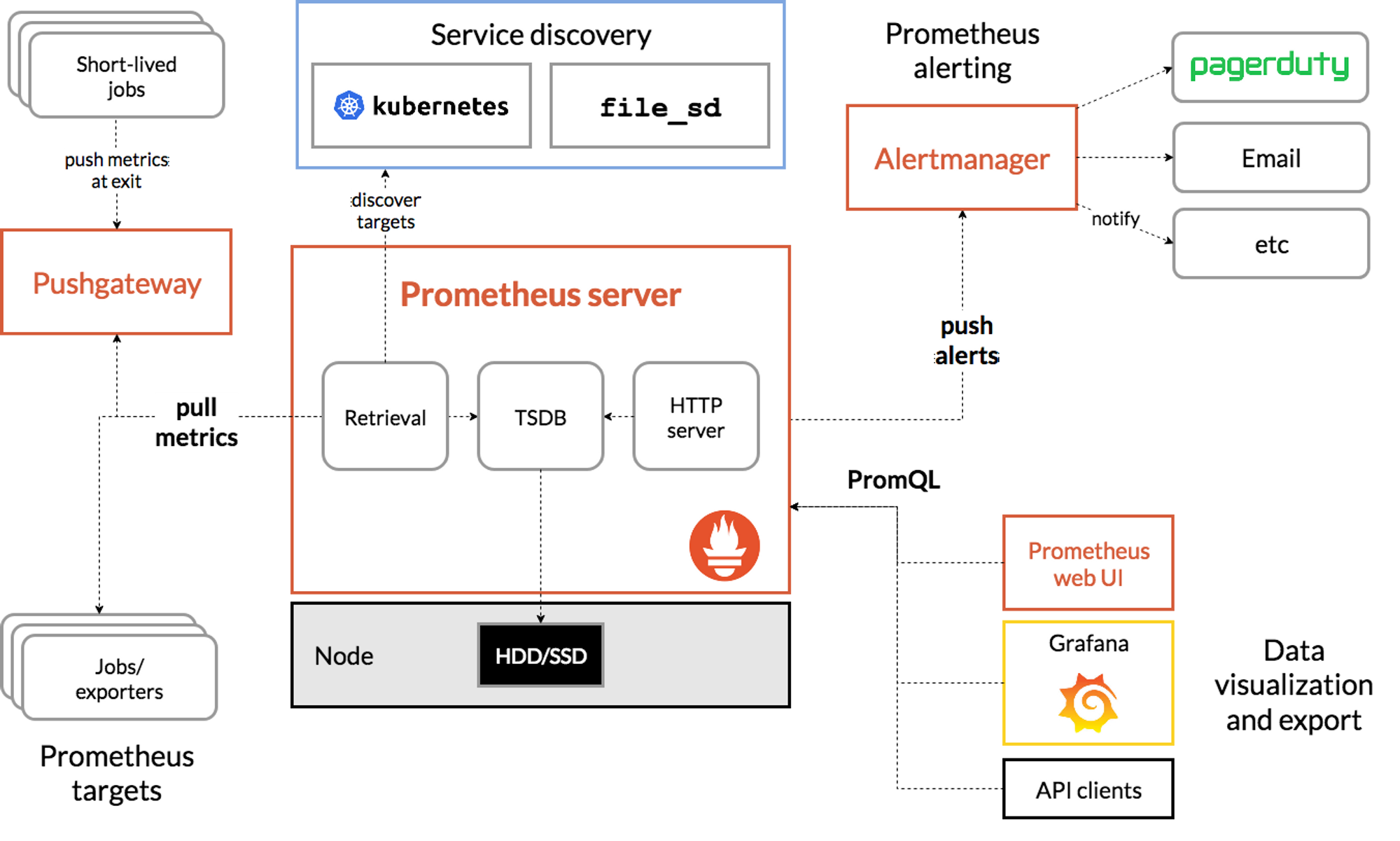
제공 기능
- 메트릭 이름과 키/값 쌍으로 식별되는 시계열 데이터(=TSDB, 시계열 데이터베이스)를 가진 다차원 데이터 모델
- 이러한 다차원성을 활용하기 위한 유연한 쿼리 언어인 PromQL
- 분산 스토리지에 대한 의존 없음; 단일 서버 노드는 자율적임
- 시계열 수집은 HTTP를 통한 pull 모델로 이루어짐
- 중간 게이트웨이를 통해 시계열 푸시를 지원함
- 대상은 서비스 디스커버리 또는 정적 구성을 통해 발견됨
- 다양한 그래프 및 대시보드 지원 모드
구성 요소
- 시계열 데이터를 스크랩하고 저장하는 주요 Prometheus 서버
- 응용 프로그램 코드를 측정하기 위한 클라이언트 라이브러리
- 단기 작업을 지원하기 위한 Push Gateway
- HAProxy, StatsD, Graphite 등과 같은 서비스를 위한 특수 목적의 Exporters
- 경고를 처리하기 위한 Alertmanager
- 다양한 지원 도구
kube-prometheus-stack 설치
kube-prometheus-stack는 Kubernetes Manifest, Grafana 대시보드, Prometheus 규칙 및 문서 및 스크립트를 수집하여, Prometheus Operator를 사용하여 Prometheus를 통한 쉬운 end-to-end Kubernetes 클러스터 모니터링을 제공합니다.
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
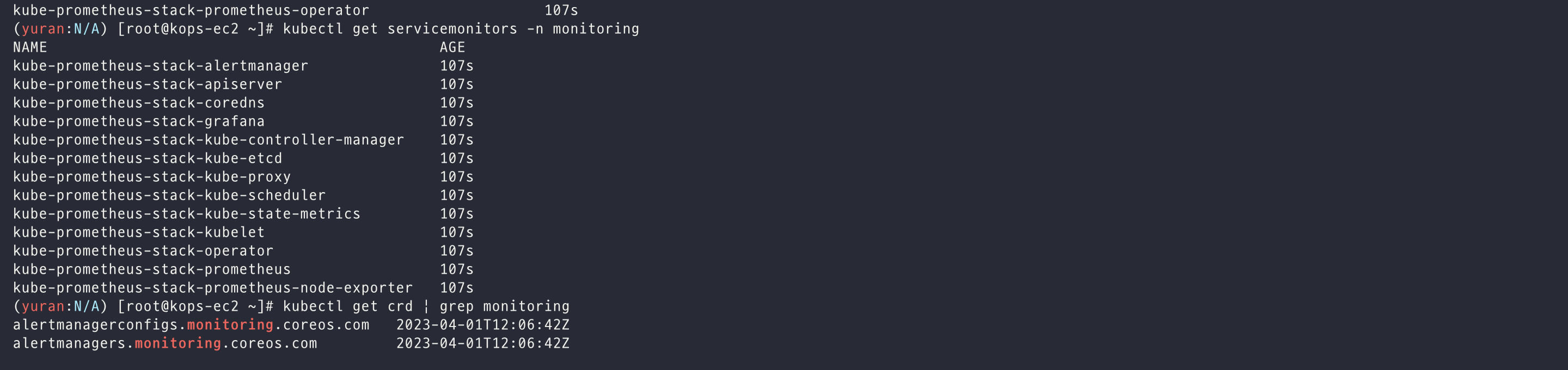
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring
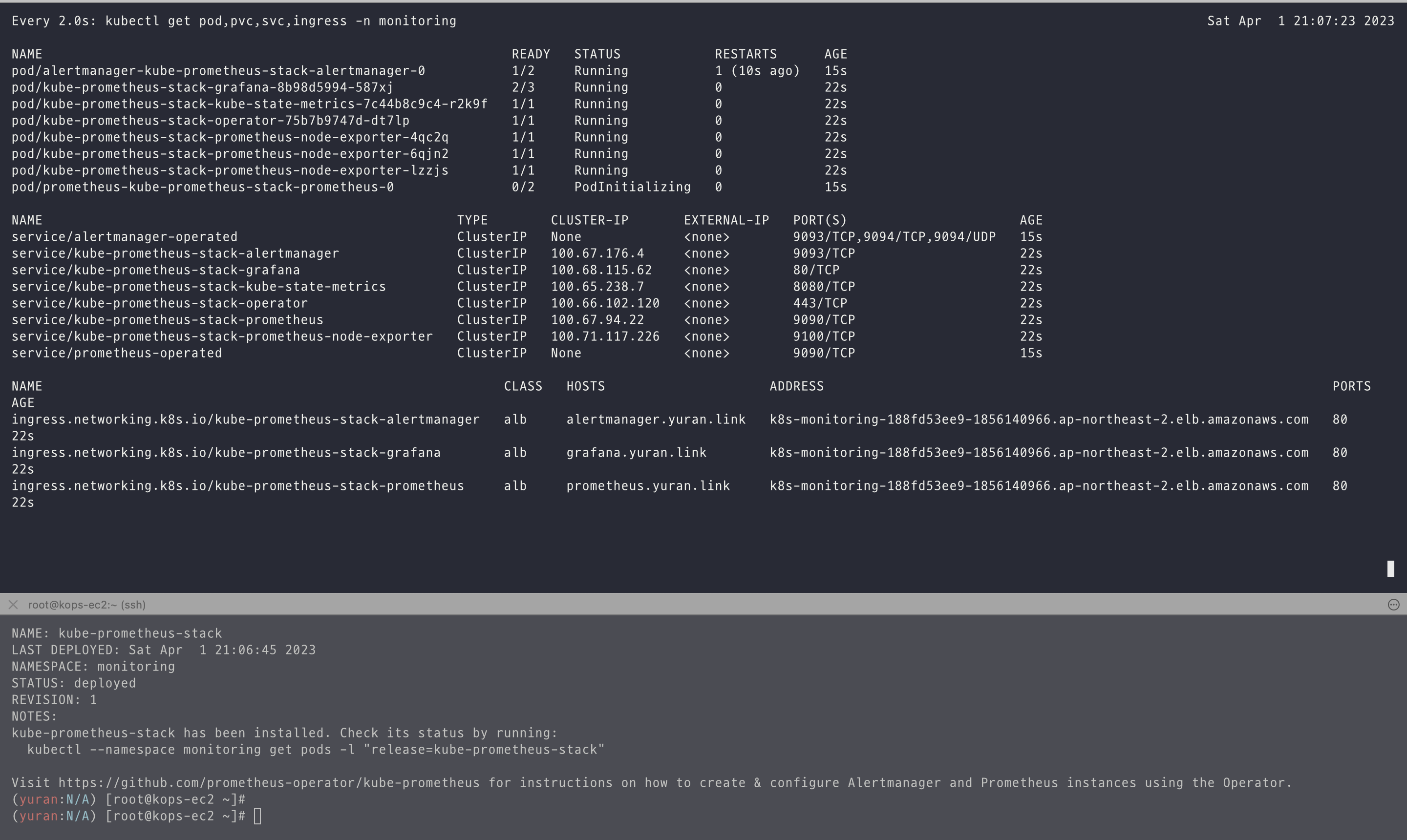
- alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
- grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
- prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
- node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
- operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
- kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
프로메테우스 기본 사용 : 모니터링 그래프
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# 마스터노드에 lynx 설치
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME hostname
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo apt install lynx -y
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME lynx -dump localhost:9100/metrics
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
4. 도움말(Help)

그라파나 Grafana
- 소개 : Grafana는 데이터 시각화, 모니터링 및 분석을 위한 인기 있는 오픈 소스 플랫폼입니다. 이를 통해 사용자는 데이터베이스, 클라우드 서비스 및 Prometheus와 같은 기타 모니터링 도구를 비롯한 다양한 소스의 실시간 데이터를 표시하는 대화형 맞춤형 대시보드를 만들 수 있습니다. Grafana는 광범위한 데이터 소스를 지원하고 Grafana Query Language(GQL)라는 강력한 쿼리 언어를 제공하여 데이터를 추출하고 조작합니다. 또한 플러그인 및 확장에 기여하는 대규모 개발자 커뮤니티가 있어 확장성과 사용자 정의가 가능합니다. Grafana는 DevOps 및 IT 운영에서 시스템 메트릭, 로그 및 애플리케이션 성능을 모니터링하고 분석하는 데 널리 사용됩니다.
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
- 접속 정보 확인 및 로그인 : 기본 계정 admin / prom-operator
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
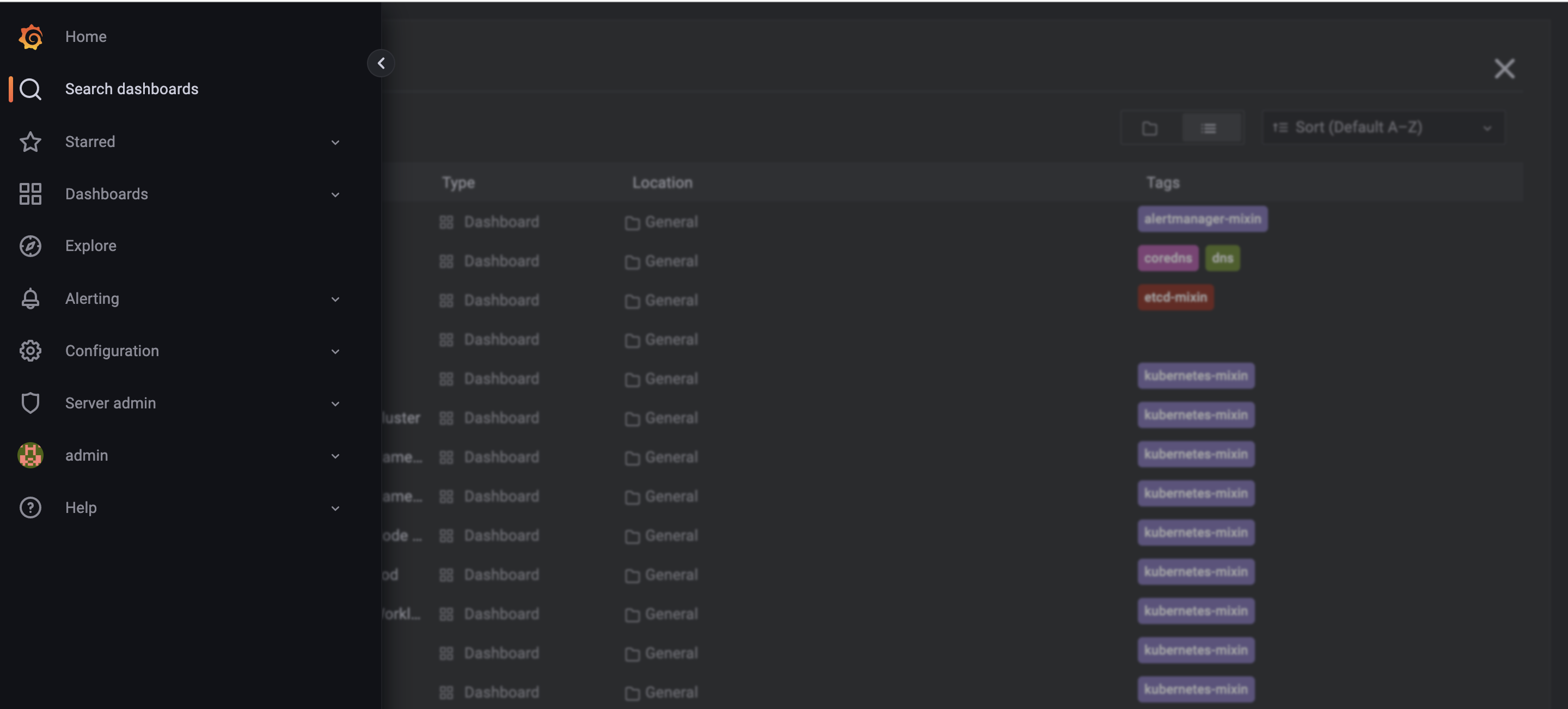
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Configuration : 설정, 예) 데이터 소스 설정 등
- Server admin : 사용자, 조직, 플러그인 등 설정
- admin : admin 사용자의 개인 설정
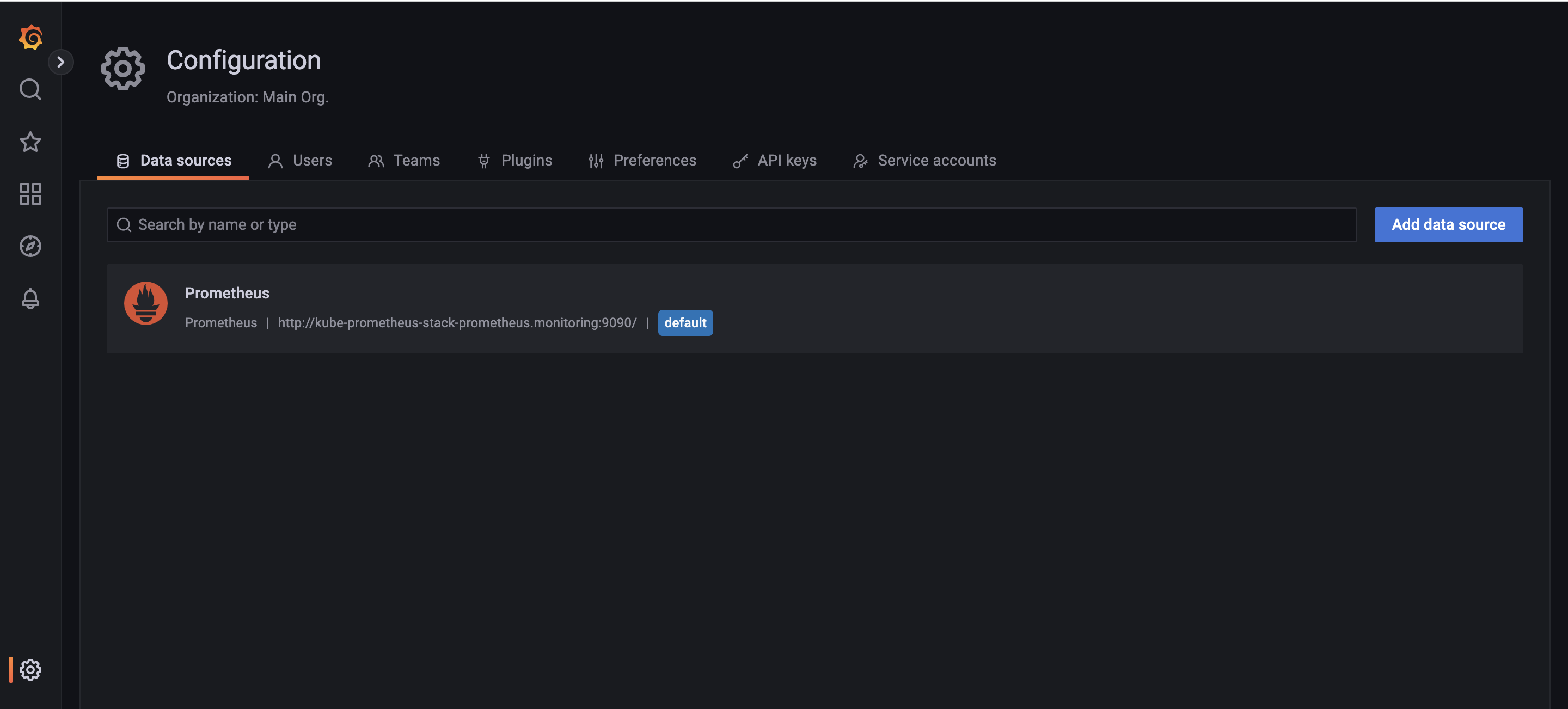
Configuration → Data sources : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인

- 해당 서비스에 접속
# 테스트용 파드 배포
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
kubectl get pod
# 접속 확인
kubectl exec -it pod-1 -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it pod-1 -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v
-
대시보드 사용 : 기본 대시보드와 공식 대시보드 가져오기
기본 대시보드- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster
공식 대시보드 가져오기- 링크
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → Import → 13770 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Kubernetes / Views / Global] Dashboard → Import → 15757 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
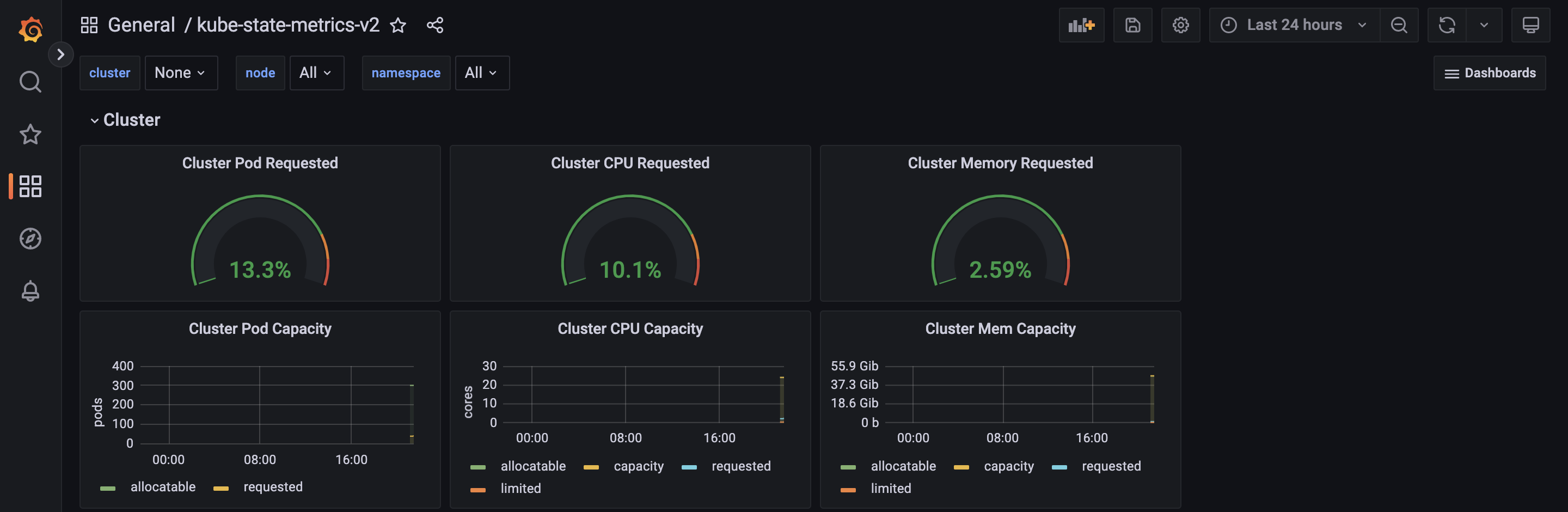
- kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Node Exporter Full] Dashboard → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
-
NGINX 웹서버 배포 및 애플리케이션 모니터링 설정 및 접속
- 서비스모니터 동작
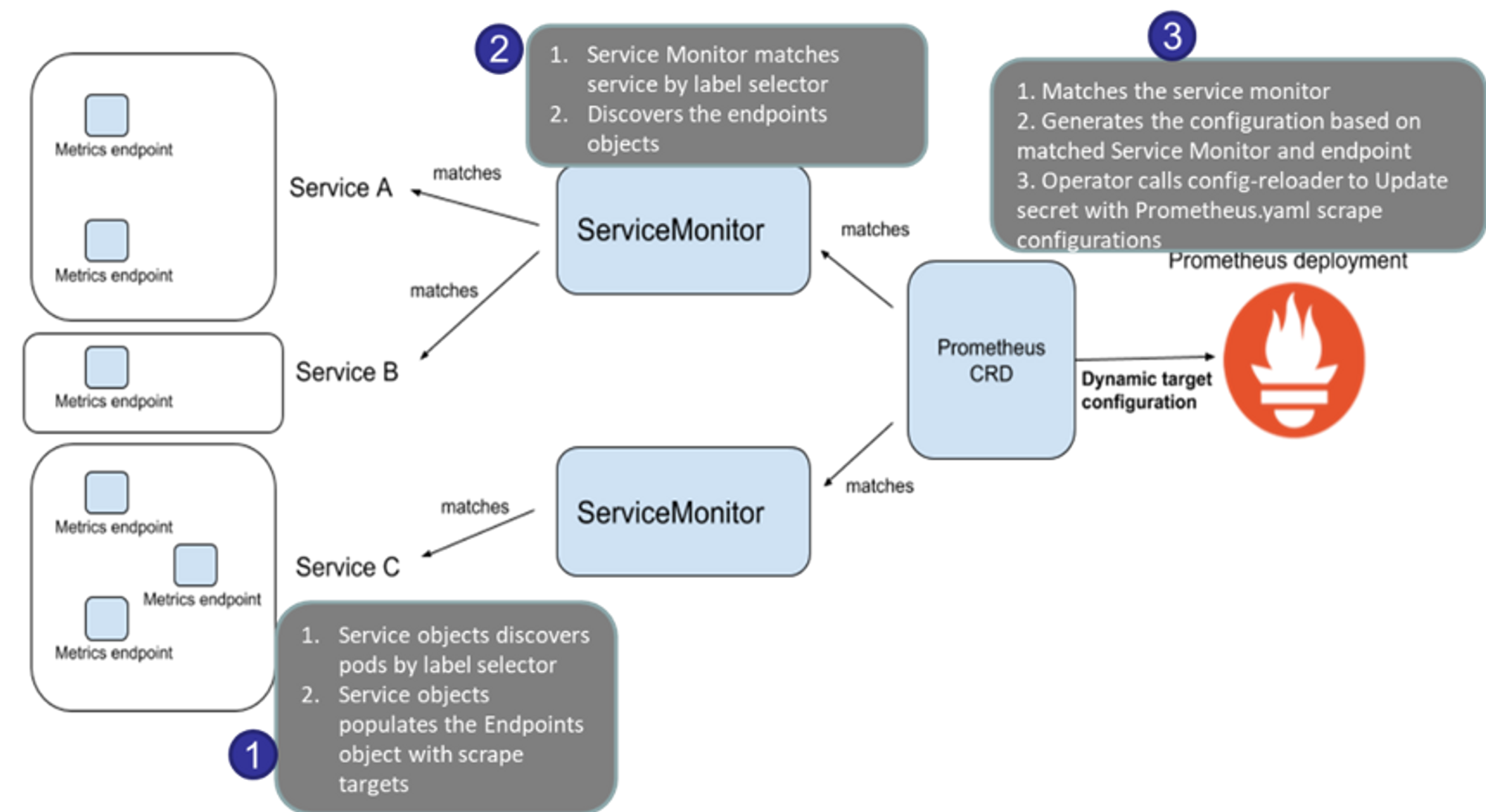
- 서비스모니터 동작
https://containerjournal.com/topics/container-management/cluster-monitoring-with-prometheus-operator/
- nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능!
- 프로메테우스 설정에서 nginx 모니터링 관련 내용을 서비스 모니터 CRD로 추가 가능!
- 기존 애플리케이션 파드에 프로메테우스 모니터링을 추가하려면 사이드카 방식을 사용하며 exporter 컨테이너를 추가!
- nginx 웹 서버 helm 설치 - Helm
helm repo add bitnami https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install nginx bitnami/nginx --version 13.2.23 -f nginx-values.yaml
# CLB에 ExternanDNS 로 도메인 연결
kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME"
curl -s http://nginx.$KOPS_CLUSTER_NAME
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done
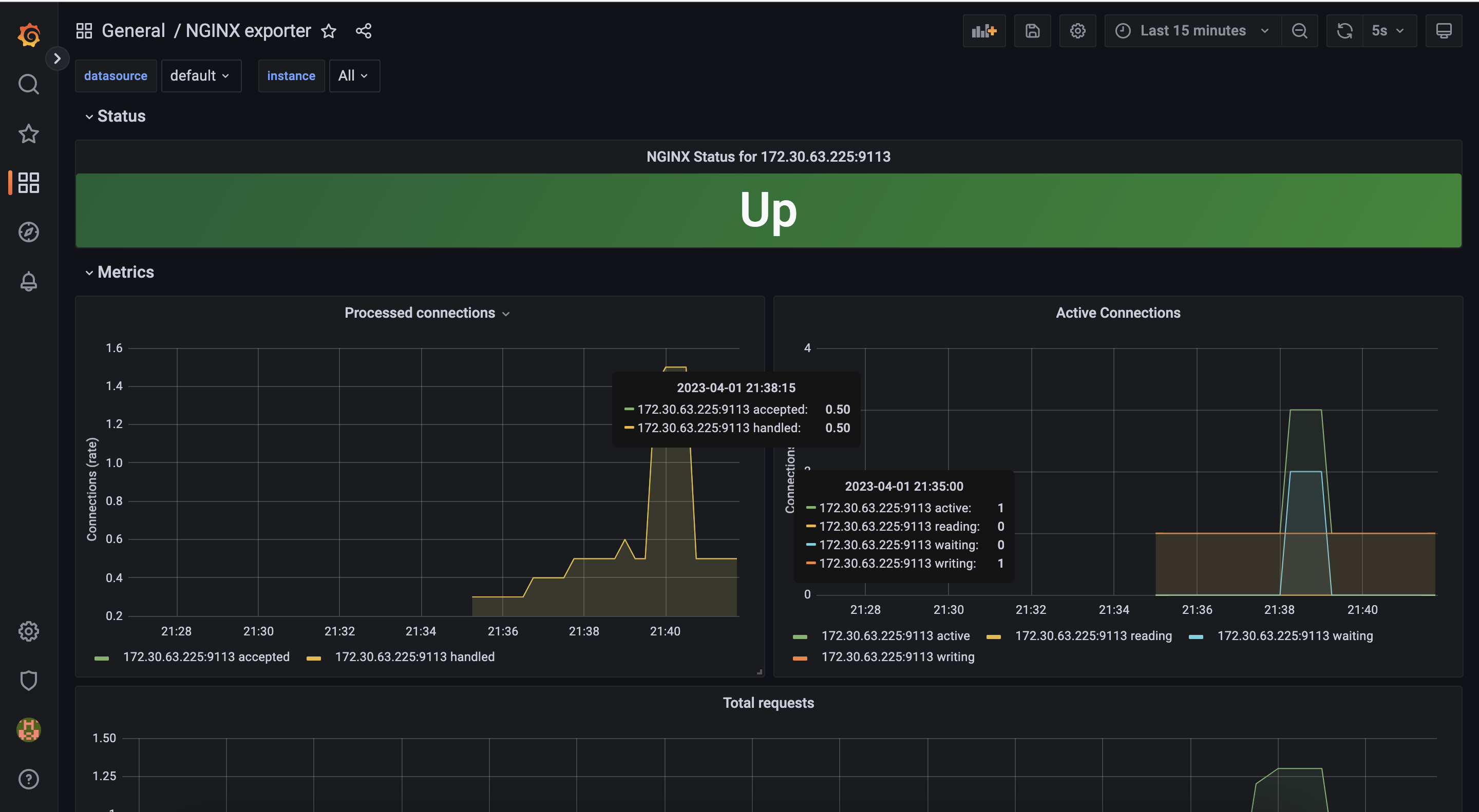
- 서비스 모니터링 생성 후 1분 정도 후에 프로메테우스 웹서버에서 State → Targets 에 nginx 서비스 모니터 추가 확인

12708번 대시보드
kwatch
kwatch는 Kubernetes(K8s) 클러스터 내에서 모든 변경 사항을 모니터링하고, 실행 중인 앱에서 충돌을 실시간으로 감지하여, 즉각적으로 채널(Slack, Discord 등)에 알림을 게시할 수 있도록 도와주는 도구입니다.
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/xxxxx
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml
Alerting 프로메테우스 얼럿매니저
프로메테우스의 임곗값 도달 시 경고 메시지를 얼럿매니저에 푸시 이벤트로 전달하고, 얼럿매지저는 이를 가공후 이메일/슬랙 등에 전달
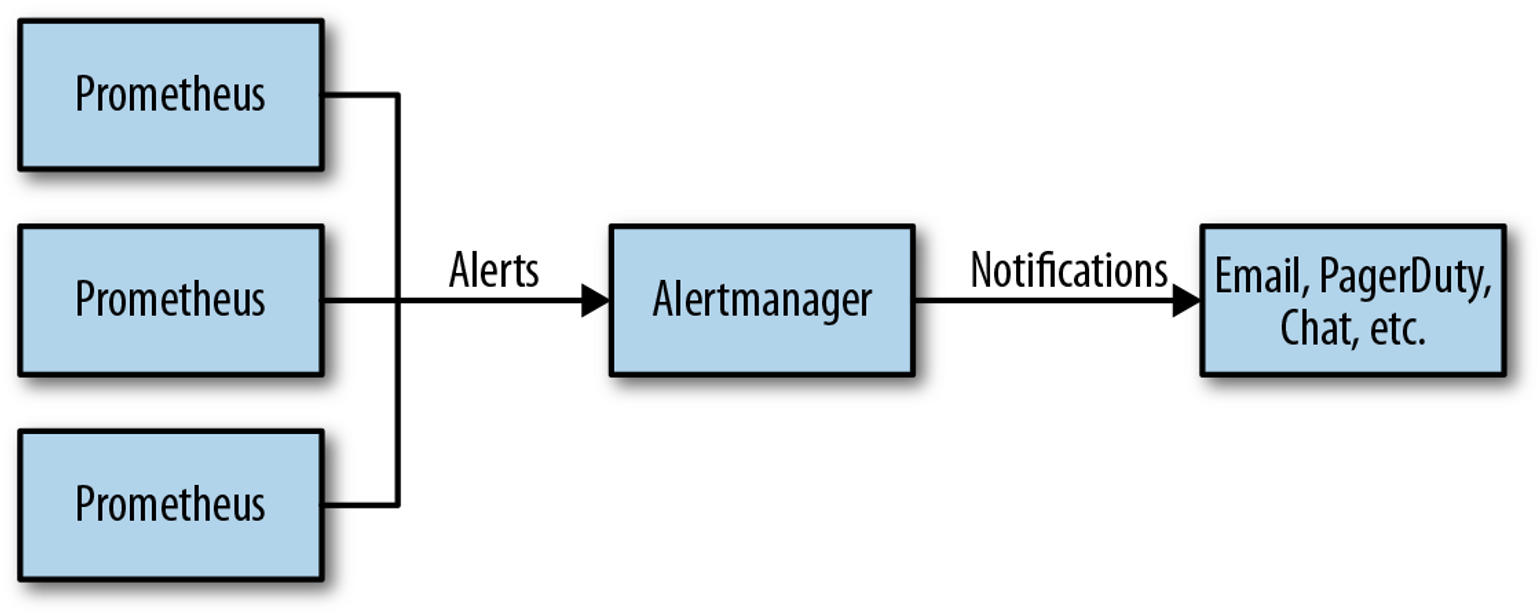
- 워커 노드 3번 추가
# EC2 인스턴스 모니터링
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --output text | sort; echo "------------------------------" ;date; sleep 1; done
# 인스턴스그룹 정보 확인
kops get ig
# 노드 추가
kops edit ig nodes-ap-northeast-2a --set spec.minSize=2 --set spec.maxSize=2
# 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster
# 워커노드 증가 확인
while true; do kubectl get node; echo "------------------------------" ;date; sleep 1; done
- 얼럿매니저 웹 접속 & 얼럿매니저 대시보드 karma 사용
# ingress 도메인으로 웹 접속
echo -e "Alertmanager Web URL = https://alertmanager.$KOPS_CLUSTER_NAME"
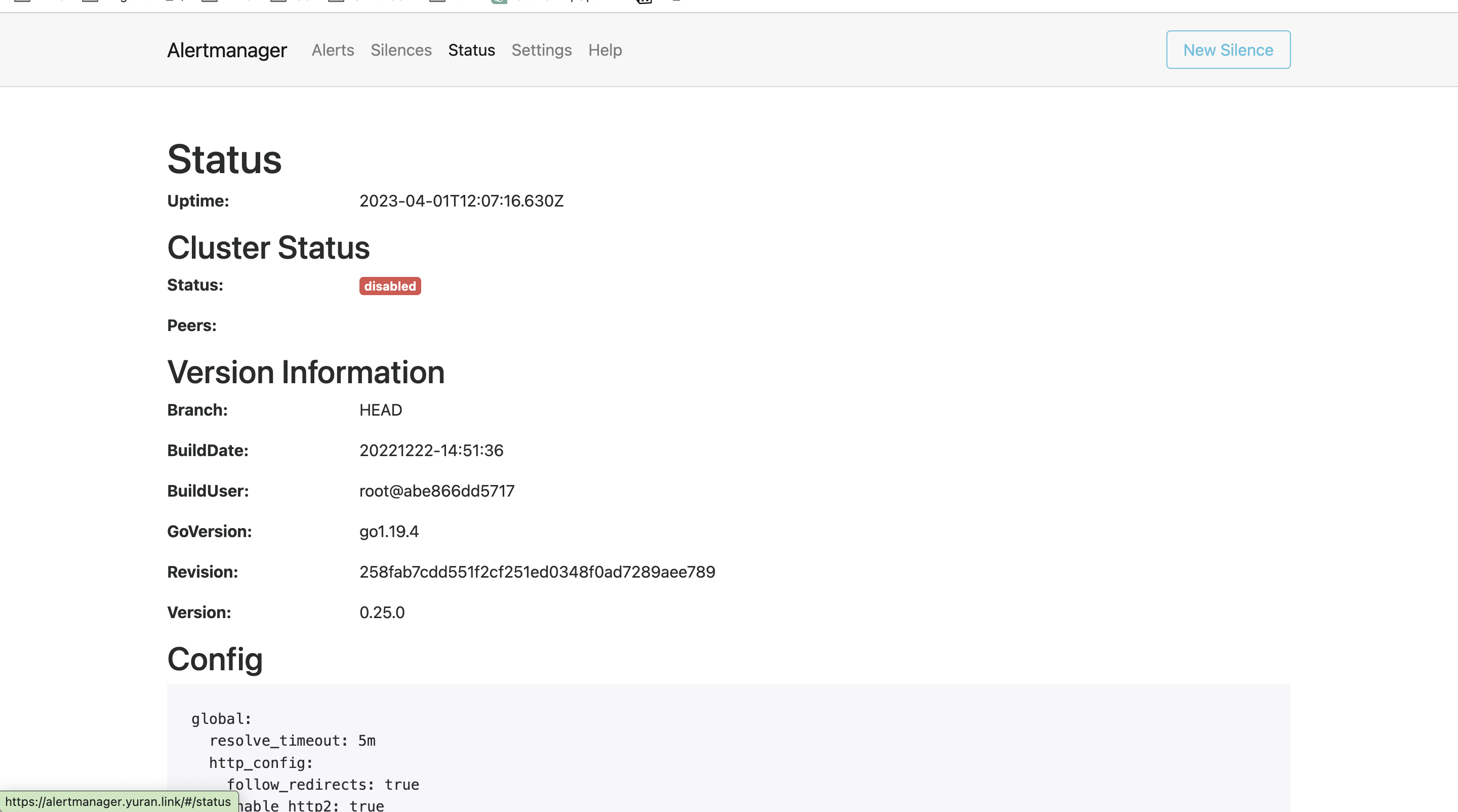
- Alerts 경고: 시스템 문제 시 프로메테우스가 전달한 경고 메시지 목록을 확인
- Silences 일시 중지 : 계획 된 장애 작업 시 일정 기간 동안 경고 메시지를 받지 않을 때, 메시지별로 경고 메시지를 일시 중단 설정
- Statue 상태 : 얼럿매니저 상세 설정 확인
- 얼럿매니저 대시보드 karma 컨테이너로 실행
# 실행
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
# 확인
docker ps
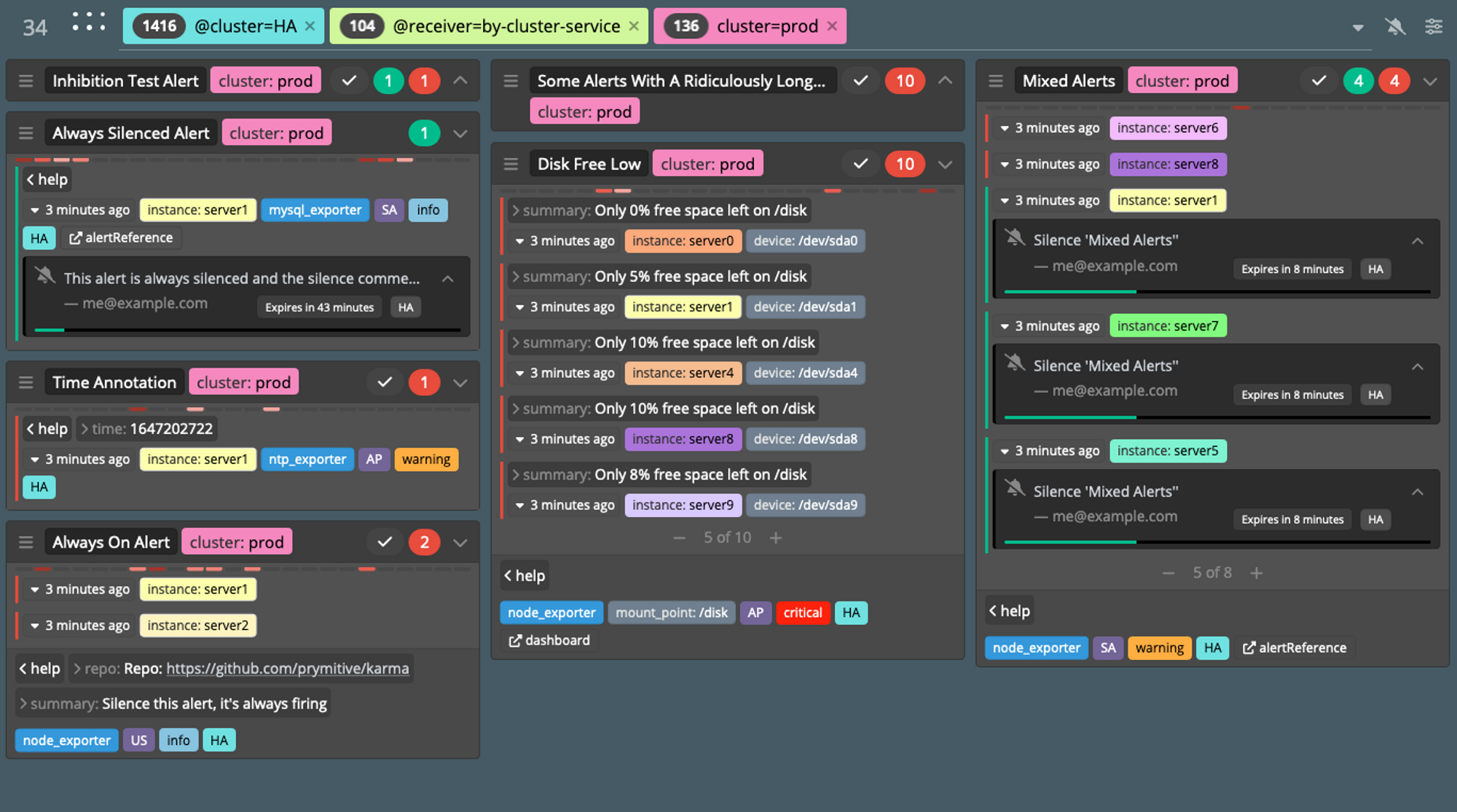
- [자신의 PC] 얼럿매니저 대시보드 karma 웹 접속 주소 확인
~ # ok 10:34:25 PM
echo -e "karma Web URL = http://$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)"
karma Web URL = http://3.36.61.187
댓글남기기